 |
4000156919 |
|
4000156919 |
來源:巨靈鳥軟件 作者:進(jìn)銷存軟件 發(fā)布:2018/3/3 瀏覽次數(shù):4766
語音識別,通常稱為自動語音識別,英文是Automatic Speech Recognition,縮寫為 ASR,主要是將人類語音中的詞匯內(nèi)容轉(zhuǎn)換為計算機(jī)可讀的輸入,一般都是可以理解的文本內(nèi)容,也有可能是二進(jìn)制編碼或者字符序列。但是,我們一般理解的語音識別其實都是狹義的語音轉(zhuǎn)文字的過程,簡稱語音轉(zhuǎn)文本識別( Speech To Text, STT )更合適,這樣就能與語音合成(Text To Speech, TTS )對應(yīng)起來。
語音識別是一項融合多學(xué)科知識的前沿技術(shù),覆蓋了數(shù)學(xué)與統(tǒng)計學(xué)、聲學(xué)與語言學(xué)、計算機(jī)與人工智能等基礎(chǔ)學(xué)科和前沿學(xué)科,是人機(jī)自然交互技術(shù)中的關(guān)鍵環(huán)節(jié)。但是,語音識別自誕生以來的半個多世紀(jì),一直沒有在實際應(yīng)用過程得到普遍認(rèn)可,一方面這與語音識別的技術(shù)缺陷有關(guān),其識別精度和速度都達(dá)不到實際應(yīng)用的要求;另一方面,與業(yè)界對語音識別的期望過高有關(guān),實際上語音識別與鍵盤、鼠標(biāo)或觸摸屏等應(yīng)是融合關(guān)系,而非替代關(guān)系。
深度學(xué)習(xí)技術(shù)自 2009 年興起之后,已經(jīng)取得了長足進(jìn)步。語音識別的精度和速度取決于實際應(yīng)用環(huán)境,但在安靜環(huán)境、標(biāo)準(zhǔn)口音、常見詞匯場景下的語音識別率已經(jīng)超過 95%,意味著具備了與人類相仿的語言識別能力,而這也是語音識別技術(shù)當(dāng)前發(fā)展比較火熱的原因。
隨著技術(shù)的發(fā)展,現(xiàn)在口音、方言、噪聲等場景下的語音識別也達(dá)到了可用狀態(tài),特別是遠(yuǎn)場語音識別已經(jīng)隨著智能音箱的興起成為全球消費電子領(lǐng)域應(yīng)用最為成功的技術(shù)之一。由于語音交互提供了更自然、更便利、更高效的溝通形式,語音必定將成為未來最主要的人機(jī)互動接口之一。
當(dāng)然,當(dāng)前技術(shù)還存在很多不足,如對于強(qiáng)噪聲、超遠(yuǎn)場、強(qiáng)干擾、多語種、大詞匯等場景下的語音識別還需要很大的提升;另外,多人語音識別和離線語音識別也是當(dāng)前需要重點解決的問題。雖然語音識別還無法做到無限制領(lǐng)域、無限制人群的應(yīng)用,但是至少從應(yīng)用實踐中我們看到了一些希望。
本篇文章將從技術(shù)和產(chǎn)業(yè)兩個角度來回顧一下語音識別發(fā)展的歷程和現(xiàn)狀,并分析一些未來趨勢,希望能幫助更多年輕技術(shù)人員了解語音行業(yè),并能產(chǎn)生興趣投身于這個行業(yè)。
語音識別的技術(shù)歷程
現(xiàn)代語音識別可以追溯到 1952 年,Davis 等人研制了世界上第一個能識別 10 個英文數(shù)字發(fā)音的實驗系統(tǒng),從此正式開啟了語音識別的進(jìn)程。語音識別發(fā)展到今天已經(jīng)有 70 多年,但從技術(shù)方向上可以大體分為三個階段。
下圖是從 1993 年到 2017 年在 Switchboard 上語音識別率的進(jìn)展情況,從圖中也可以看出 1993 年到 2009 年,語音識別一直處于 GMM-HMM 時代,語音識別率提升緩慢,尤其是 2000 年到 2009 年語音識別率基本處于停滯狀態(tài);2009 年隨著深度學(xué)習(xí)技術(shù),特別是 DNN 的興起,語音識別框架變?yōu)?DNN-HMM,語音識別進(jìn)入了 DNN 時代,語音識別精準(zhǔn)率得到了顯著提升;2015 年以后,由于“端到端”技術(shù)興起,語音識別進(jìn)入了百花齊放時代,語音界都在訓(xùn)練更深、更復(fù)雜的網(wǎng)絡(luò),同時利用端到端技術(shù)進(jìn)一步大幅提升了語音識別的性能,直到 2017 年微軟在 Swichboard 上達(dá)到詞錯誤率 5.1%,從而讓語音識別的準(zhǔn)確性首次超越了人類,當(dāng)然這是在一定限定條件下的實驗結(jié)果,還不具有普遍代表性。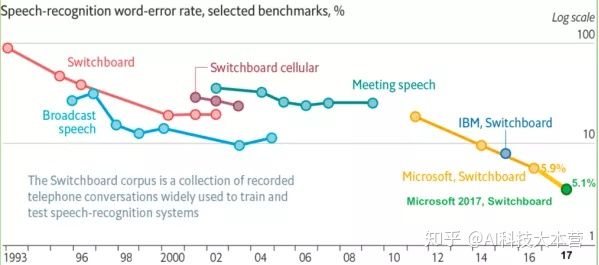
GMM-HMM時代
70 年代,語音識別主要集中在小詞匯量、孤立詞識別方面,使用的方法也主要是簡單的模板匹配方法,即首先提取語音信號的特征構(gòu)建參數(shù)模板,然后將測試語音與參考模板參數(shù)進(jìn)行一一比較和匹配,取距離最近的樣本所對應(yīng)的詞標(biāo)注為該語音信號的發(fā)音。該方法對解決孤立詞識別是有效的,但對于大詞匯量、非特定人連續(xù)語音識別就無能為力。因此,進(jìn)入 80 年代后,研究思路發(fā)生了重大變化,從傳統(tǒng)的基于模板匹配的技術(shù)思路開始轉(zhuǎn)向基于統(tǒng)計模型(HMM)的技術(shù)思路。
HMM 的理論基礎(chǔ)在 1970 年前后就已經(jīng)由 Baum 等人建立起來,隨后由 CMU 的 Baker 和 IBM 的 Jelinek 等人將其應(yīng)用到語音識別當(dāng)中。HMM 模型假定一個音素含有 3 到 5 個狀態(tài),同一狀態(tài)的發(fā)音相對穩(wěn)定,不同狀態(tài)間是可以按照一定概率進(jìn)行跳轉(zhuǎn);某一狀態(tài)的特征分布可以用概率模型來描述,使用最廣泛的模型是 GMM。因此 GMM-HMM 框架中,HMM 描述的是語音的短時平穩(wěn)的動態(tài)性,GMM 用來描述 HMM 每一狀態(tài)內(nèi)部的發(fā)音特征。
基于 GMM-HMM 框架,研究者提出各種改進(jìn)方法,如結(jié)合上下文信息的動態(tài)貝葉斯方法、區(qū)分性訓(xùn)練方法、自適應(yīng)訓(xùn)練方法、HMM/NN 混合模型方法等。這些方法都對語音識別研究產(chǎn)生了深遠(yuǎn)影響,并為下一代語音識別技術(shù)的產(chǎn)生做好了準(zhǔn)備。自上世紀(jì) 90 年代語音識別聲學(xué)模型的區(qū)分性訓(xùn)練準(zhǔn)則和模型自適應(yīng)方法被提出以后,在很長一段內(nèi)語音識別的發(fā)展比較緩慢,語音識別錯誤率那條線一直沒有明顯下降。
DNN-HMM時代
2006年,Hinton 提出深度置信網(wǎng)絡(luò)(DBN),促使了深度神經(jīng)網(wǎng)絡(luò)(DNN)研究的復(fù)蘇。2009 年,Hinton 將 DNN 應(yīng)用于語音的聲學(xué)建模,在 TIMIT 上獲得了當(dāng)時最好的結(jié)果。2011 年底,微軟研究院的俞棟、鄧力又把 DNN 技術(shù)應(yīng)用在了大詞匯量連續(xù)語音識別任務(wù)上,大大降低了語音識別錯誤率。從此語音識別進(jìn)入 DNN-HMM 時代。
DNN-HMM主要是用 DNN 模型代替原來的 GMM 模型,對每一個狀態(tài)進(jìn)行建模,DNN 帶來的好處是不再需要對語音數(shù)據(jù)分布進(jìn)行假設(shè),將相鄰的語音幀拼接又包含了語音的時序結(jié)構(gòu)信息,使得對于狀態(tài)的分類概率有了明顯提升,同時DNN還具有強(qiáng)大環(huán)境學(xué)習(xí)能力,可以提升對噪聲和口音的魯棒性。
簡單來說,DNN 就是給出輸入的一串特征所對應(yīng)的狀態(tài)概率。由于語音信號是連續(xù)的,不僅各個音素、音節(jié)以及詞之間沒有明顯的邊界,各個發(fā)音單位還會受到上下文的影響。雖然拼幀可以增加上下文信息,但對于語音來說還是不夠。而遞歸神經(jīng)網(wǎng)絡(luò)(RNN)的出現(xiàn)可以記住更多歷史信息,更有利于對語音信號的上下文信息進(jìn)行建模。
由于簡單的 RNN 存在梯度爆炸和梯度消散問題,難以訓(xùn)練,無法直接應(yīng)用于語音信號建模上,因此學(xué)者進(jìn)一步探索,開發(fā)出了很多適合語音建模的 RNN 結(jié)構(gòu),其中最有名的就是 LSTM 。LSTM 通過輸入門、輸出門和遺忘門可以更好的控制信息的流動和傳遞,具有長短時記憶能力。雖然 LSTM 的計算復(fù)雜度會比 DNN 增加,但其整體性能比 DNN 有相對 20% 左右穩(wěn)定提升。
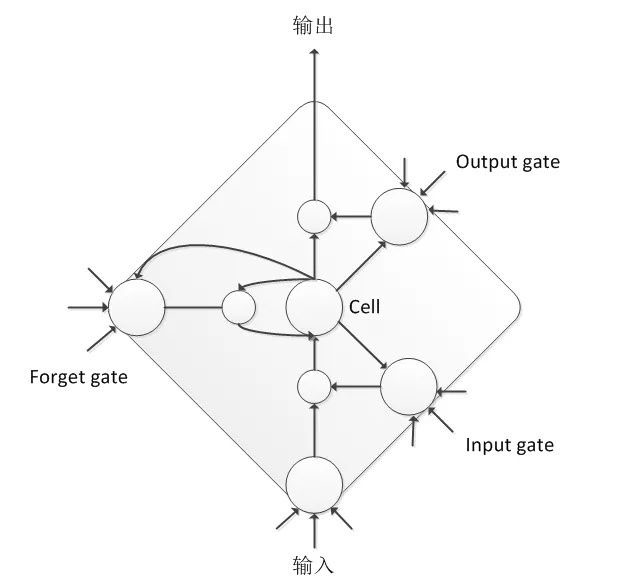
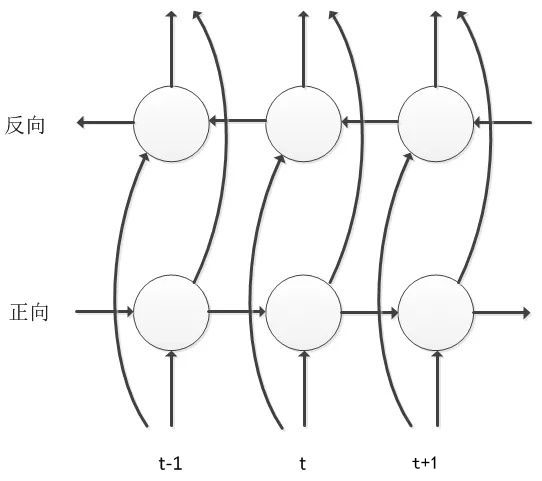
BLSTM 是在 LSTM 基礎(chǔ)上做的進(jìn)一步改進(jìn),不僅考慮語音信號的歷史信息對當(dāng)前幀的影響,還要考慮未來信息對當(dāng)前幀的影響,因此其網(wǎng)絡(luò)中沿時間軸存在正向和反向兩個信息傳遞過程,這樣該模型可以更充分考慮上下文對于當(dāng)前語音幀的影響,能夠極大提高語音狀態(tài)分類的準(zhǔn)確率。BLSTM 考慮未來信息的代價是需要進(jìn)行句子級更新,模型訓(xùn)練的收斂速度比較慢,同時也會帶來解碼的延遲,對于這些問題,業(yè)屆都進(jìn)行了工程優(yōu)化與改進(jìn),即使現(xiàn)在仍然有很多大公司使用的都是該模型結(jié)構(gòu)。
圖像識別中主流的模型就是 CNN,而語音信號的時頻圖也可以看作是一幅圖像,因此 CNN 也被引入到語音識別中。要想提高語音識別率,就需要克服語音信號所面臨的多樣性,包括說話人自身、說話人所處的環(huán)境、采集設(shè)備等,這些多樣性都可以等價為各種濾波器與語音信號的卷積。而 CNN 相當(dāng)于設(shè)計了一系列具有局部關(guān)注特性的濾波器,并通過訓(xùn)練學(xué)習(xí)得到濾波器的參數(shù),從而從多樣性的語音信號中抽取出不變的部分,CNN 本質(zhì)上也可以看作是從語音信號中不斷抽取特征的一個過程。CNN 相比于傳統(tǒng)的 DNN 模型,在相同性能情況下,前者的參數(shù)量更少。
綜上所述,對于建模能力來說,DNN 適合特征映射到獨立空間,LSTM 具有長短時記憶能力,CNN 擅長減少語音信號的多樣性,因此一個好的語音識別系統(tǒng)是這些網(wǎng)絡(luò)的組合。
來源:巨靈鳥 歡迎分享本文
上一個文章:技術(shù)一旦被用來作惡,究竟會有多可怕(一)
下一個文章:語音識別技術(shù)簡史(二)